my-anki-reviews
物流行业信息咨询RAG系统
1 背景介绍
近一年以来,随着ChatGPT的火爆,使得LLM成为研究和应用的热点,但是市面上大部分LLM都存在一个共同的问题:模型都是基于过去的经验数据进行训练完成,无法获取最新的知识,以及各企业私有的知识。因此很多企业为了处理私有的知识,主要借助一下两种手段来实现:
- 利用企业私有知识,基于开源大模型进行微调
- 基于LangChain集成向量数据库以及LLM搭建本地知识库的问答(RAG)
本次项目以”某物流行业”为例,基于物流信息构建RAG系统,测试问答效果。注意:除物流场景外,使用者可以自由切换其他行业类型知识,实现本地知识库问答的效果。
2 RAG原理
该项目的基本原理:
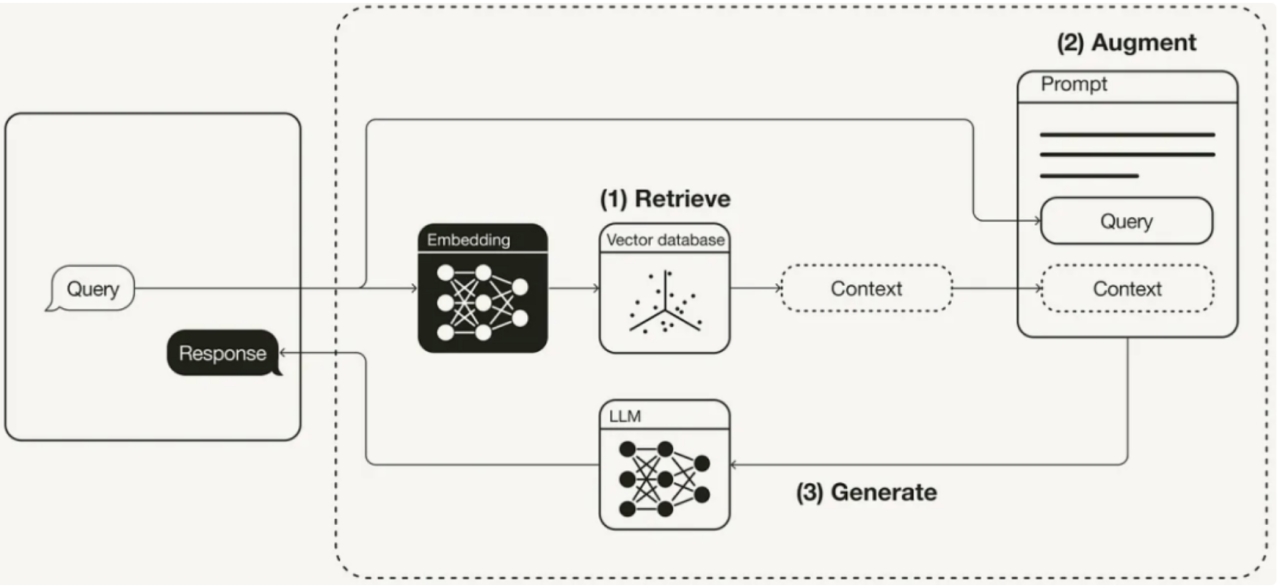
3 项目流程
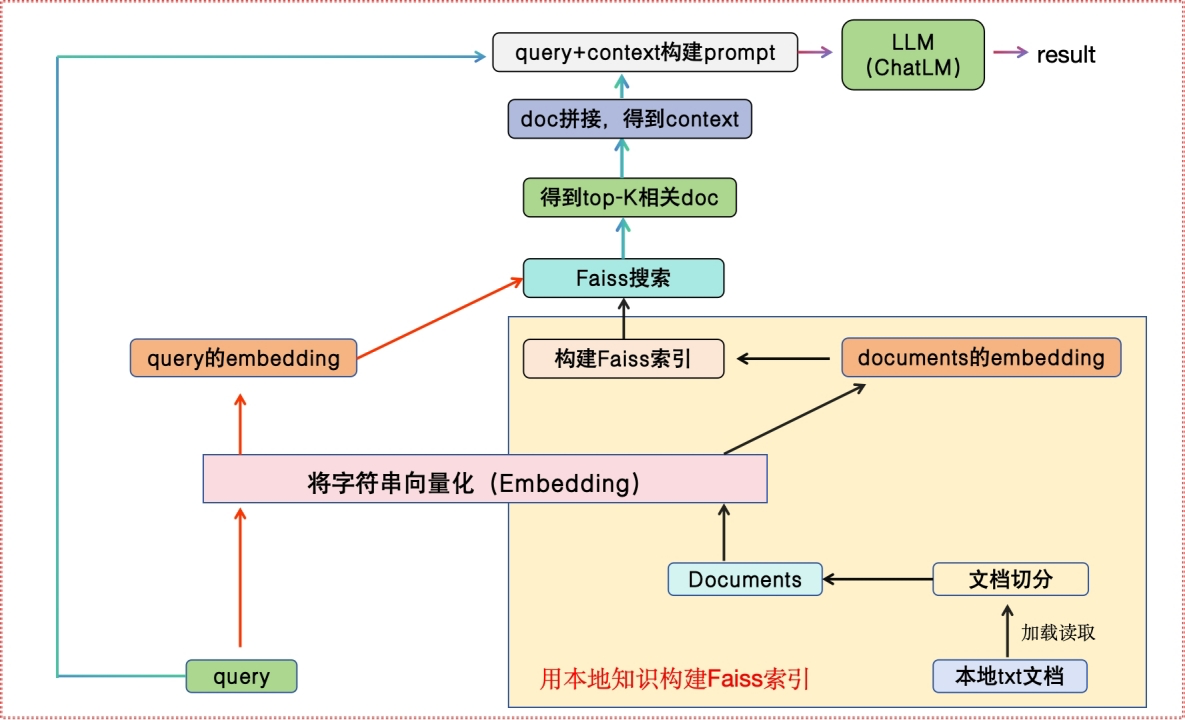
4 环境配置
4.1 安装依赖
- 首先,确保你的机器安装了Python3.8-Python3.11
# 终端查看python的版本
python --version
- 紧接着安装项目的依赖
# 安装全部依赖
pip install faiss-cpu
pip install langchain
pip install ollama
4.2 模型下载
如需在本地或离线环境下运行本项目,需要首先将项目所需的模型下载至本地,本地将基于Ollama第三方管理框架,实现模型的下载和管理.
5 代码实现
5.1 本地知识库构建
- 将本地pdf文档信息进行抽取,然后进行分块,最后Embedding存储向量数据库中
- 代码示例:
from langchain_community.document_loaders import PyMuPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.vectorstores import FAISS # 向量数据库
def get_vector():
# 第一步:加载文档
loader = PyMuPDFLoader("物流信息.pdf")
# 将文本转成 Document 对象
data = loader.load()
print(f'data:{len(data)}')
# 第二步:切分文本
text_splitter = RecursiveCharacterTextSplitter(chunk_size=50, chunk_overlap=20)
# 切割加载的 document
split_docs = text_splitter.split_documents(data)
print("split_docs size:", len(split_docs))
print(split_docs)
# 第三步:初始化 hugginFace 的 embeddings 对象
embeddings = OllamaEmbeddings(model="mxbai-embed-large", temperature=0)
# 第四步:将 document通过embeddings对象计算得到向量信息并永久存入FAISS向量数据库,用于后续匹配查询
db = FAISS.from_documents(split_docs, embeddings)
db.save_local("./faiss/wuliu")
if __name__ == '__main__':
result = get_vector()
5.2 构建本地问答RAG系统
- 代码示例:
# coding:utf-8
# 导入必备的工具包
from langchain import PromptTemplate
from local_db import *
from langchain_community.llms import Ollama
import time
# 加载FAISS向量库
embeddings = OllamaEmbeddings(model="mxbai-embed-large", temperature=0)
db = FAISS.load_local("faiss/wuliu",embeddings, allow_dangerous_deserialization=True)
# db = FAISS.load_local("faiss/wuliu", embeddings)
start_time = time.time()
def get_related_content(related_docs):
related_content = []
for doc in related_docs:
# print(f'doc.page_content--》{doc.page_content}')
related_content.append(doc.page_content.replace("\n\n", "\n"))
print(f'related_content列表状态--》{related_content}')
return "\n".join(related_content)
def define_prompt():
question = '我的快递出发地是哪?预计几天的时间到达?'
docs = db.similarity_search(question, k=2)
print(f'docs--》{docs}')
related_content = get_related_content(docs)
print(f'related_content字符串状态-->{related_content}')
print('*'*80)
PROMPT_TEMPLATE = """
基于以下已知信息,简洁和专业的来回答用户的问题。不允许在答案中添加编造成分。
已知内容:
{context}
问题:
{question}"""
prompt = PromptTemplate(
input_variables=["context", "question"],
template=PROMPT_TEMPLATE,)
my_pmt = prompt.format(context=related_content,
question=question)
return my_pmt
def qa():
model = Ollama(model="qwen2.5:7b")
my_pmt = define_prompt()
result = model.invoke(my_pmt)
return result
if __name__ == '__main__':
result = qa()
print(result)
end_time = time.time()
print(end_time-start_time)
5.3 构建web界面实现RAG检索
- 代码示例:
from local_qa import *
from langchain.chains import ConversationalRetrievalChain
import streamlit as st
# 设置标题
st.set_page_config(page_title="物流行业信息咨询系统", layout="wide")
st.title("物流行业信息咨询系统")
# 初始化全局变量
chat_history = []
# 定义检索链函数
def new_retrival():
"""
创建基于 ConversationalRetrievalChain 的问答链。
"""
chain = ConversationalRetrievalChain.from_llm(
llm=Ollama(model="qwen2.5:7b"), # 使用本地大模型
retriever=db.as_retriever() # 基于本地数据库的检索器
)
return chain
# 主逻辑
def main():
"""
Streamlit 主页面的交互逻辑。
"""
# 初始化会话状态
if "messages" not in st.session_state:
st.session_state.messages = [] # 用于保存聊天记录
# 展示历史聊天记录
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"]) # 显示消息内容
# 接受用户输入
if prompt := st.chat_input("请输入你的问题:"):
# 保存用户消息到会话状态
st.session_state.messages.append({"role": "user", "content": prompt})
# 显示用户输入
with st.chat_message("user"):
st.markdown(prompt)
# 调用模型获取回答
with st.chat_message("assistant"):
# 占位符用于显示逐字生成的回答
message_placeholder = st.empty()
full_response = ""
# 调用检索链获取答案
chain = new_retrival()
result = chain.invoke({"question": prompt, "chat_history": chat_history})
chat_history.append((prompt, result["answer"])) # 更新聊天历史
assistant_response = result["answer"]
# 模拟流式回答(逐字显示)
for chunk in assistant_response.split():
full_response += chunk + " "
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
# 保存回答到会话状态
st.session_state.messages.append({"role": "assistant", "content": full_response})
# 运行主逻辑
if __name__ == "__main__":
main()
- 结果展示:
